
FuriosaAI Aims to Transform AI Accelerator Market with TCP
FuriosaAI Aims to Transform AI Accelerator Market with TCP
Posted April. 10, 2025 10:34,
Updated April. 11, 2025 09:49
Introduced the TCP to revolutionize AI accelerator market
Launched ‘RNGD’ in 2024, shown promising results in global PoC engagement
Back in 2006, when Nvidia unveiled its new G80 series graphics cards, they introduced introducing a technology called GPGPU that allows gaming graphics cards to be used as general-purpose computing cards. GPGPU, which stands for General-Purpose computing on Graphics Processing Units, is a technology that connects a graphics pipeline to allow the GPU to perform application computations that were previously handled by the CPU. And CUDA, the programming language that supports it, has created an environment that allows developers to perform a wide variety of mathematical operations with GPUs.

NVIDIA GPU's use and value has shaken the world through GPGPU technology
At that time, Nvidia CEO Jensen Huang envisioned that graphics cards would be used for computing, not gaming, and the implementation of floating-point on Nvidia GPUs was configured to be close to the IEEE(Institute of Electrical and Electronics Engineers) standard. As the scope of what could be done with NVIDIA graphics cards expanded, many programs began to be built on top of CUDA, and NVIDIA's GPGPU technology became the standard for almost any task that required computation.
Now, about two-decades later, GPUs are used in every high-performance computing task. Their ability to massively parallelize data makes them ideal for accelerated computing schemes like data servers, and they're used for computations in every area such as science, finance, artificial intelligence, simulation, data analytics and so on. NVIDIA GPUs are in supply shortage because they are the basic infrastructure for building accelerated computing at scale.
GPU for General Purpose… But poor power efficiency

The biggest advantage of GPUs lies in their general-purpose capabilities, as the term GPGPU implies. However, this comes at a cost — high power consumption and expensive product price.
The biggest advantage of GPGPUs is that they can be used for any task that requires computational processing. Today, they're used for AI and machine learning, scientific research and simulation, gaming and graphics, cloud computing, and more. But this comes at a cost. While Nvidia's GPUs have great computational performance, they are focused on peak performance rather than power efficiency.
Going back to the original, GPUs are designed for graphical computation. So when it comes to AI, there are limitations related to data processing bottleneck, inefficiencies in handling various types of tensors and memory bandwidth. Although we cannot deny GPUs are the most powerful AI accelerator currently developed, it is the result of applying more power and using more advanced designs with bigger size while sacrificing power efficiency. This is the main reason for Microsoft developing SMRs(small modular reactors) to supply power in AI development.

FuriosaAI's second-generation AI accelerator, RNGD(pronounced “Renegade”) FuriosaAI introduced a new concept called TCP (Tensor Contraction Processor) from the traditional NPU approach
As an alternative to GPUs, a new concept called NPU (Neural Processing Unit) is on the rise. NPU is the processor that mimics the way the brain works and is specialized for specific AI processing, such as deep learning. It is not as generally-purposed as a GPU, but its architecture is optimized for matrix multiplication or convolution. In addition, it is power efficient for specific AI tasks, which its performance is higher when the same power is applied. In Korea, FuriosaAI’s Warboy and Rebellion’s Atom are representative, and Cerebras, Groq and Tenstorrent are also pioneering the market.
FuriosaAI introduces new possibilities with TCP (Tensor Contraction Processor)
However, the biggest limitation of NPUs is their limited use. FuriosaAI's first-generation accelerator, Warboy, is optimized for vision recognition inference, and Rebellion’s Atom is also optimized for vision recognition, natural language processing and other inferences. To expand NPU’s applicability, Tenstorrent is developing programmable RISC-V processors. In this situation, FuriosaAI adopts the Tensor Contraction Processor (TCP) method to present new possibilities to the market.

Published paper’s preface, presented at ISCA on 2024 July
FuriosaAI presented a paper titled “TCP: A Tensor Contraction Processor for AI Workloads” at the International Symposium on Computer Architecture (ISCA) on June 2024, which covered the core processing method and technology history of its second-generation AI accelerator, Renegade. ISCA is the world's premier computer technology symposium organized by the Institute of Electrical and Electronics Engineers (IEEE) and the Association for Computing Machinery (ACM).
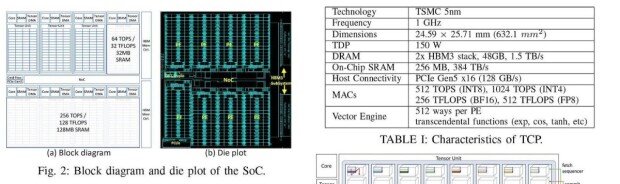
Basic structure of the TCP system-on-chip (SoC) described in the paper
FuriosaAI’s TCP is built around tensor contraction as its core computation unit. By maximizing data reuse, it significantly boosts AI processing performance. A tensor is a multi-dimensional data structure, and tensor contraction reduces certain dimensions by aggregating data, producing lower-dimensional results. While GPUs typically map tensor contractions onto matrix multiplications, this approach often fails to fully exploit the inherent parallelism and data locality of the operation. Moreover, when the processing unit size is small, data reuse becomes limited, and GPUs struggle to efficiently handle tensors with diverse shapes and dimensions — ultimately leading to suboptimal performance.
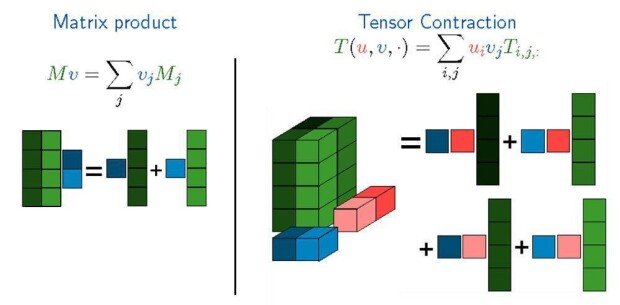
Tensor contraction is an operation that reduces the dimensionality of a multi-dimensional tensor by aggregating the data along a particular axis
TCP processes tensor contractions directly, as its fundamental computational primitive. By treating tensor contraction as a first-class primitive computation, TCP unlocks massive parallelism and fine-grained execution across a wide variety of tensor shapes and sizes. To handle a wide range of tensor processing — from small operations to high-performance computing — TCP integrates eight Processing Elements (PEs). Unlike conventional GPUs, which face limitations in reusing data and often suffer from bottlenecks when the same data is accessed repeatedly, TCP is architected to promote efficient data reuse and delivery at the hardware level.
TCP’s advanced compiler further enhances efficiency by optimizing tensor operations based on deployment scenarios. It decomposes large computations into smaller operations, rearranges them, and then reassembles them into larger workloads optimized for execution. The compiler selects the appropriate hardware instructions and compiles them into executable binaries.
The entire execution flow can be likened to cooking: starting with breaking down a recipe into steps like chopping vegetables or grilling meat, then selecting the right tools like knives and pans, and finally executing each step in the most efficient way. Similarly, TCP structures and optimizes AI workloads for maximum processing efficiency.
TCP Delivers Up to 80% of H100 Performance at Less Than One-Quarter the Power Budget
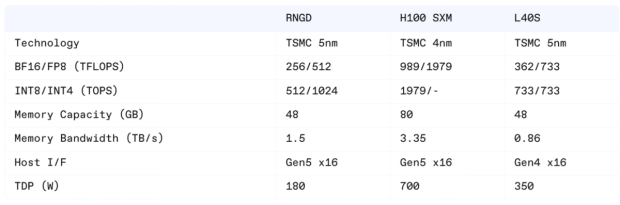
Spec comparison between Nvidia L40s, H100 and TCP(RNGD)
FuriosaAI’s Tensor Contraction Processor (TCP) is built with a thermal design power (TDP) of just 180W—significantly lower than Nvidia’s L40s (350W) and H100 (700W). While TDP doesn’t directly translate to real-world power consumption, it indicates cooling requirements and expected power draw under load. In terms of memory, TCP is equipped with 48GB of HBM3, while the L40s uses 48GB of GDDR6 and the H100 features 80GB of HBM3. In terms of raw performance, TCP achieves 512 TFLOPS in FP8 and 1024 TOPS in INT4, while L40s hits 733 FP8 TFLOPS, 733 INT4 TOPS and H100 hits 1,979 FP8 TFLOPS, 1,979 INT8 TOPS. The INT4 performance for the L40s and H100 is listed as 733 TOPS and not officially listed, respectively, as peak INT4 values rely on sparsity optimizations that are not guaranteed in typical workloads.”
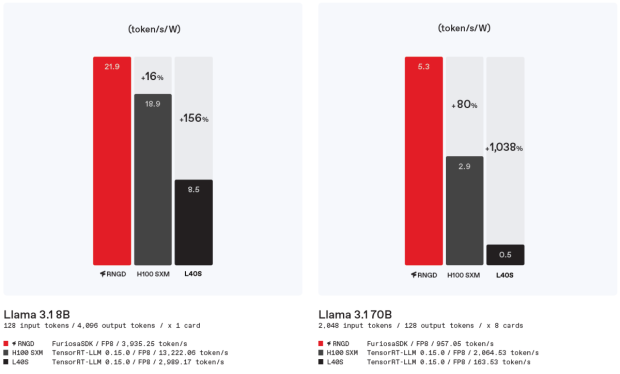
Power Efficiency comparison in Llama 3.1 scenario between TCP and GPU
When it comes to performance-per-watt, TCP demonstrates clear advantages. When running the Llama 3.1 8B(Number of parameter, benchmark performance gets better when parameters are getting bigger in normal case) model, TCP achieves 156% greater energy efficiency than L40s and 16% better than H100. Although absolute throughput still favors Nvidia—TCP generates 3,935 tokens per second versus H100’s 13,222—the real story lies in cost-efficiency. For AI service providers and datacenter operators, Total Cost of Ownership (TCO)—which includes performance, power efficiency, and hardware cost—is the most crucial metric. Considering power efficiency as well as Nvidia’s expensive pricing, TCP might be an attractive option.
The advantage becomes even more pronounced with larger models. For Llama 3.1 70B, TCP achieves approximately 80% of H100’s energy efficiency and over 1000% of L40s', with a throughput of 957 tokens/sec compared to H100’s 2,064. While absolute throughput remains higher on the H100, TCP’s superior power efficiency presents a strong TCO advantage, especially in inference-focused and power-constrained environments such as data centers.
TCP Opens a New Frontier for General-Purpose NPUs
While traditional NPUs are optimized for specific tasks using fixed-function compute units, TCP employs eight processing elements (PEs) and a fetch network designed to efficiently deliver and reuse data. This architecture allows TCP to handle tensor operations with greater flexibility than conventional NPUs, narrowing the flexibility gap with GPUs.

FuriosaAI second-generation RNGD board
The implications are significant. GPUs were dominating in AI industry due to their general-purpose nature, despite their power inefficiency and high cost. And conventional NPUs have typically served only narrow inference use cases, positioning them as supplementary rather than competitive. However, TCP challenges this paradigm by enabling a wider range of AI tasks without sacrificing power or area efficiency.
While GPU users may be hesitant to switch, FuriosaAI is actively working to lower the adoption barrier—offering tools that optimize and deploy models directly onto TCP. The product, now branded as RNGD (Pronounced “Renegade”), debuted in August 2024.
Since its launch in August, RNGD has entered proof-of-concept (PoC) engagements with prominent global customers, including LG and Aramco. Early performance results from these trials have shown compelling efficiency and throughput, validating RNGD’s real-world competitiveness.
RNGD is now available for evaluation and deployment at a mass production level as well. With a vertically integrated software stack, advanced compiler support, and market-proven energy efficiency, FuriosaAI is offering an alternative to traditional AI accelerators. As global demand for scalable and sustainable AI compute is on the rise, FuriosaAI is well-positioned to lead the next wave of innovation in the AI accelerator industry.
By Si Hyeon Nam (sh@itdonga.com)





